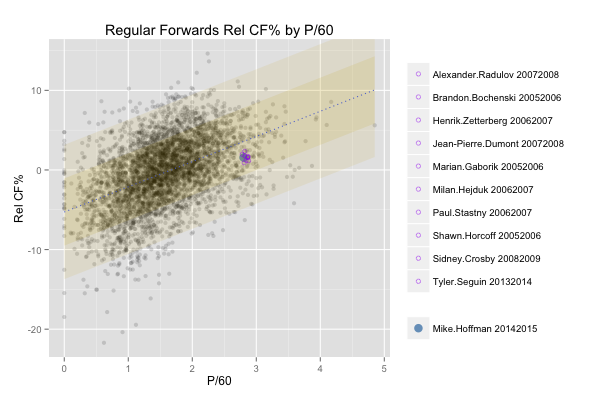
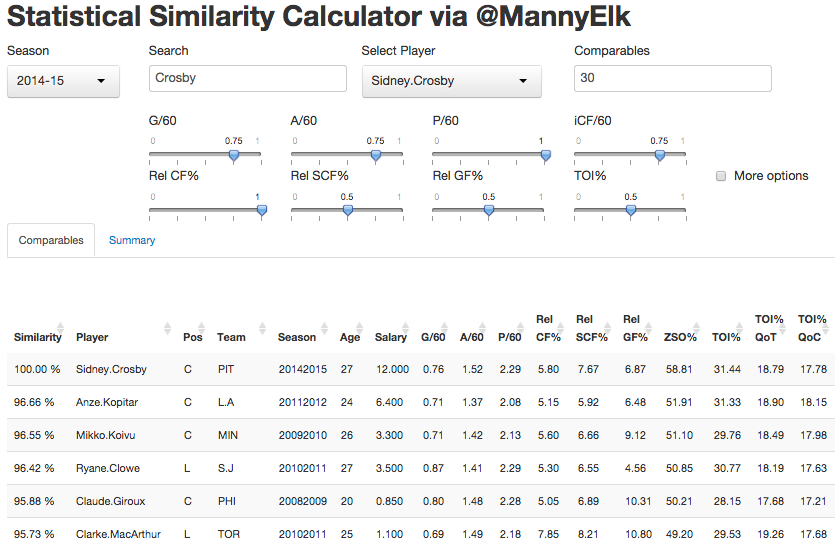
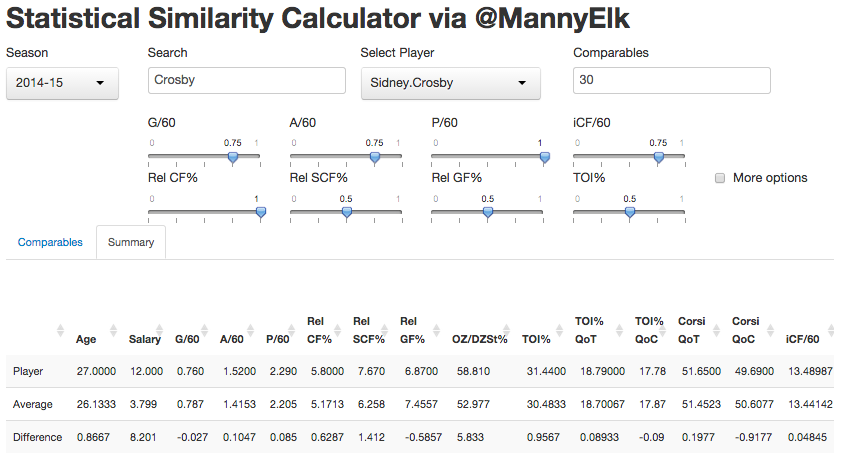
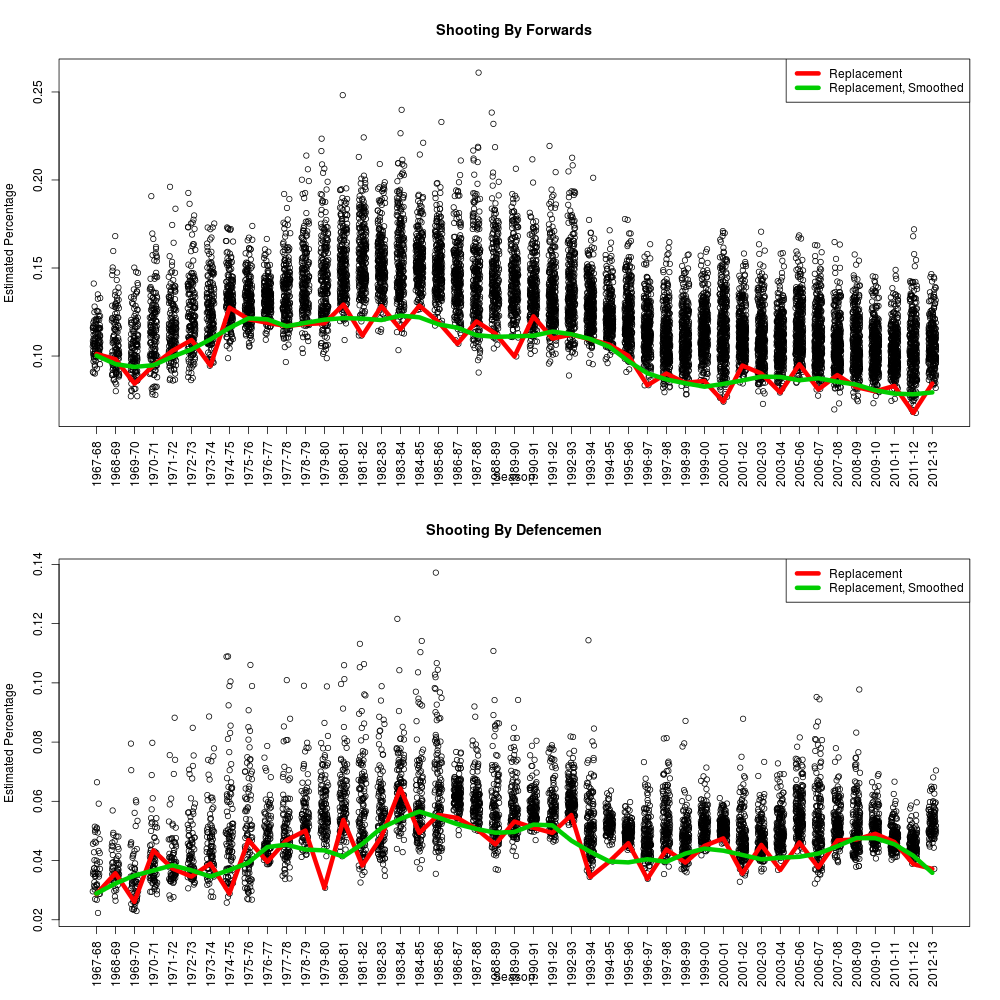
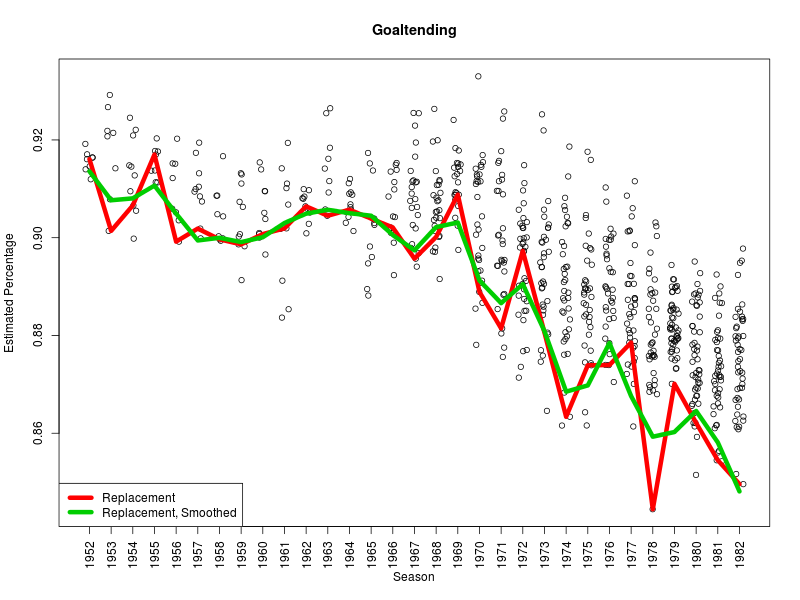
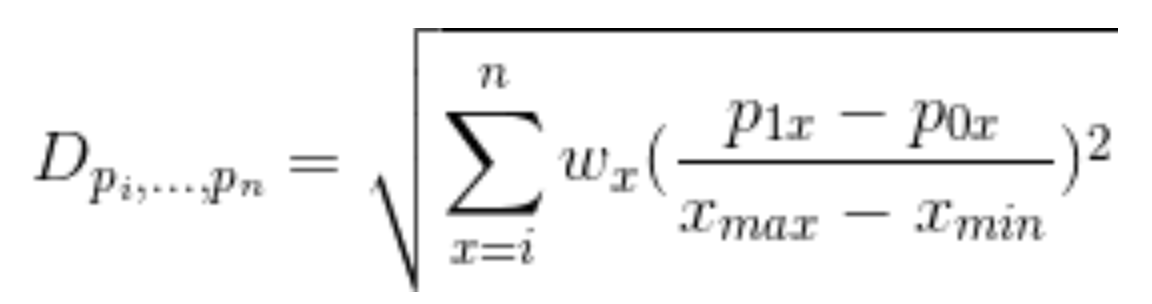I’ve been curious for a while about the impact of rest and travel on goaltending, especially after reading the work of Gus Katsaros and Eric Tulsky, so I re-ran the numbers on save percentages including back to back games, away versus home and with danger zones included. We know that shooting rates for go down and rates against go up, especially for high danger shots, when teams play back to back games; this is enough to make me wonder whether our enhanced database will tell us more with goaltending than we previously knew.
Eric Tulsky previously found that the back-to-back edge was worth a full percentage point in the second half of back to backs, from .912 to 901, using data from the 2011-12 and 2012-13 seasons. Since we now have data at war-on-ice.com with quality goaltending data from 2005-06 until this season (2014-15), it’s worth a fresh look. Here’s the effective difference by season.
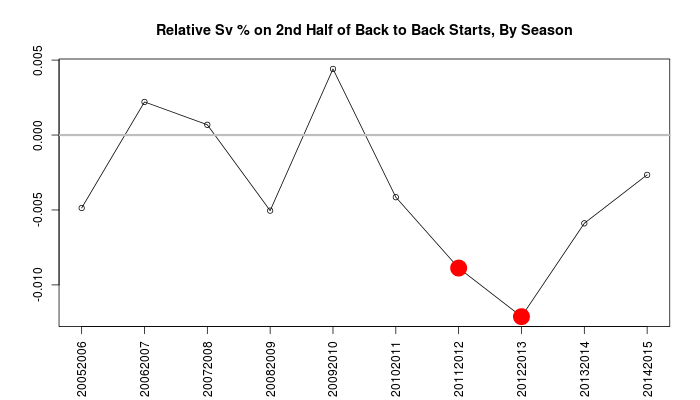
The reputation for tired goalies has apparently been made based on the two worst years in our record; in fact, in three other seasons the effective change in save percentage is positive.
Given the additional tools we have at our disposal, let’s break them out and see if they tell us anything new about this. Let’s do it in this sequence using good old logistic regression:
- Start with the home advantage, the indicator for the second half of a back to back, and the interaction between the two.
- Add in danger zones, since we know this has played a role.
- Add score difference, since teams with the lead have higher shooting percentages.
- Add in the game state (5v5, PP, SH, 4v4, etc)
- Finally, we add in terms for each goaltender in case there are selection effects for which coaches are willing to lean on their number ones.
The negative changes in save “percentage” in thousandths for each factor:
| Model | Away Goalie | Back-To-Back (Home) | Back-To-Back (Away) |
|---|---|---|---|
| 1 | 3.3 | 1.3 | 3.1 |
| 2 | 1.2 | 2.1 | 3.4 |
| 3 | 0.6 | 1.9 | 3.4 |
| 4 | 0.1 | 1.8 | 2.9 |
| 5 | -0.03 | 2.3 | 3.7 |
The home advantage on save percentage disappears the more factors we add, and the difference in “tired” performance persists, but only at 3 and a half points below their usual performance, not 11. I was personally expecting the differences to be bigger, and I was also expecting shot danger to play a bigger role than effectively none. Still, while we still don’t have a good idea if it’s there’s greater risk for injury, or other unknown factors, we can be confident that coaches aren’t completely nuts if they send their Number One out back to back.
Replication materials: