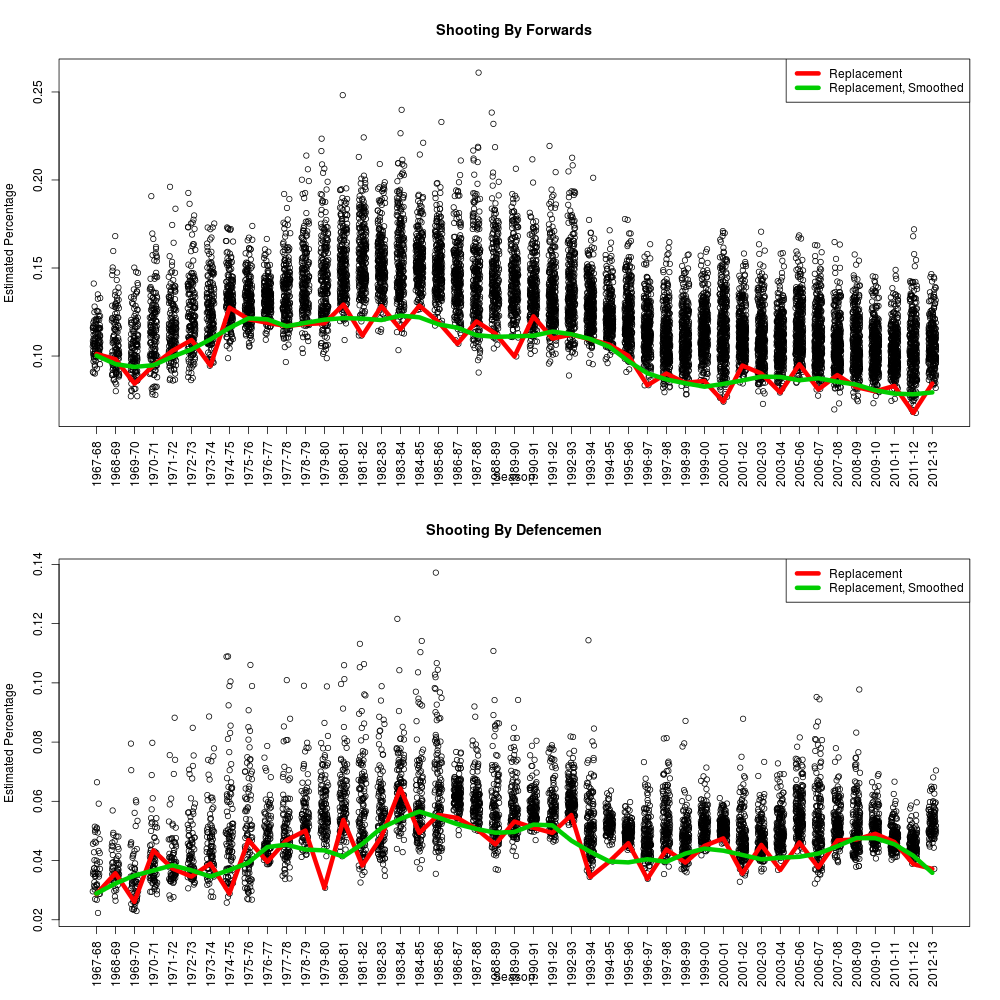
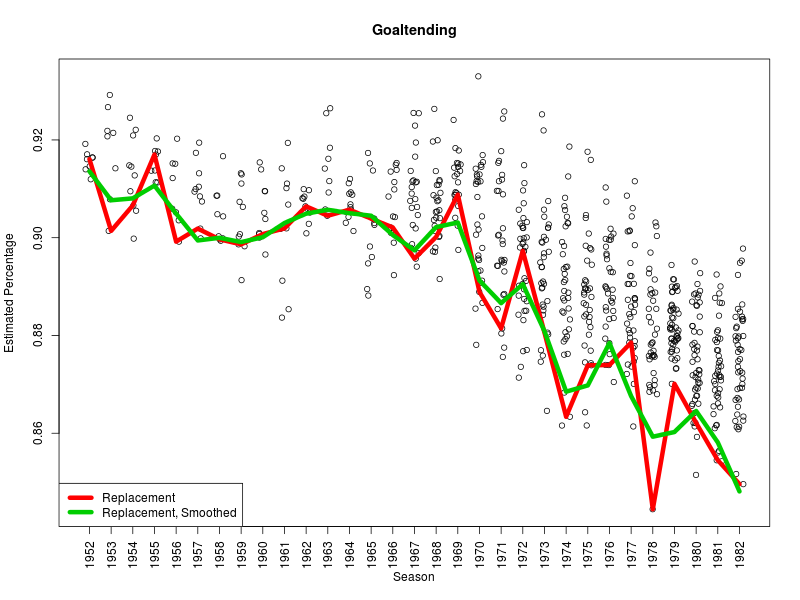
One of the biggest questions when it comes to WAR is exactly what question we’re trying to answer by constructing these measures. There are a few that we need to address, because they’re often all asked at once.
- What actually happened?
- What would have happened, given what we know now, and events repeated over again?
- What would have happened (if we had made a change)?
- What’s going to happen next?
- What will happen next, if we can make a change?
For each of these points, the answer seems clear. The biggest issue is that they often overlap, and figuring out exactly what questions we’re answering is a bit more difficult. When it comes to what we’re trying to learn about players,
What actually happened?
This is the most clear-cut to express. The numbers themselves are not adjusted for anything; players with abnomally high shooting percentages get to keep the goals they scored, and defensemen who allow a large number of shots are still victimized by their iess competent linemates in the final totals. And ultimately, this is how we measure performance.
The problem is, these measures are meaningless without context. In the strictest sense, it’s impossible to compare two player performances because we can’t known exactly how player A would have performed in the events in which player B was involved.
This is why…
What would have happened (if we had made a change)?
is the midpoint that lets us answer those questions, since the change in question is “what if we swapped out our player in question and replayed the game over?”
This is the simplest adjustment: a baseline for context. What would be expected to happen to a stand-in player in similar circumstances? “Average” levels are a reasonable start, but we endorse the idea of “replacement” because that’s our best guess of who would have to take that job next if something came up.
So for the purposes of WAR, we’re not making adjustments to the actual observed events, only to what we expect would have happened. And its primary purpose is not to forecast future performance. This is the current approach we’re using for our WAR measures, partly because it’s the least difficult to understand, but we’re not limited to it.
Best widespread sports example: MVP voting (eventually).
This connects to…
What would have happened, given what we know now, and events repeated over again?
This is what we’re getting at when we try to measure talent; if the situation repeated itself, with the same conditions, what kind of an outcome would we be most likely to see.
This can involve quite a bit of adjustment, mostly to get rid of noise in small samples but also to gain strength from the system as a whole. Results that are inconsistent with others are treated with suspicion and examined carefully.
Best widespread sports example: Barstool arguments over who was better, Gretzky or Lemieux, if they happened between Sam and Andrew.
What’s going to happen next?
This is pure prediction — gambling if you’re losing, arbitrage if you’re winning. We don’t get to fiddle any knobs, change any rosters or have any kind of pretend control over the future. Our only task is to guess what’s to come and with what certainty.
The distinct thing about this is that the proof of the pudding is in the eating: it doesn’t really matter to people how you cooked up your estimates, because credibility is earned by being right more often in the long run.
Best widespread and legal sports example: Fantasy leagues.
What will happen next, if we can make a change?
Ideally this is a question that connects back through the previous threads: screening out noise, estimating talent levels, forecasting forward and projecting to future outcomes — given that we have decisions to make and courses to change.
By and large this is separate from the immediate question of estimating WAR for past seasons, particularly if it’s a question of performance measurement and not talent. But it is connected in that it would be worth knowing what skills are worth what amount in salary and development.
Best example: The actual business of sports.